



開発・リリースフローの変化 ~サーバーレスアーキテクチャで何が変わるのか~

サーバーレスアーキテクチャで何が変わるのか
- 2017年公開(2021年改訂) ─ サーバーレスアーキテクチャで何が変わるのか
- 2021年11月公開 ─ サーバーレスアーキテクチャにおけるフロントエンドの変化
- 2022年 3月公開 ─ Web3層アプリケーションとの比較
- 2022年 4月公開 ─ サーバーレスアプリケーションの認証と認可
- 2022年 5月公開 ─ サーバーレスアーキテクチャにおけるバックエンドとバッキングサービス
- 2022年 7月公開(本記事) ─ 開発・リリースフローの変化
1. ロボット管理プラットフォーム連携基盤の構築
サーバーレスアーキテクチャ、特に昨今の技術ではリリースフローやその仕組みツールもすでに変化している。以下に例をあげる。
- クラウドリソースはCloudFormation、Terraformなどのコードで定義する
- クラウドリソースもアプリケーションのビルド・デプロイと類似したフローで作成される
- その中に内包されるアプリケーションはクラウドリソース側の仕様次第で同時にリリースすることしか出来ないものもあるし、別々に管理することが出来るもの、任意に選べるものもある
- 別々に管理することが出来るものは(AWSにおける例としてはECSのタスク定義がそれに該当するが)バージョンは前に進むことしか出来ない仕様になっている
- ECSもKubernetes(EKS)は任意に選ぶことが出来る機能を内包しているが、その仕組みをどう活用するかは使う側に委ねられている
- AWS Lambdaも同等の機能を持っているが、この仕組みはECSとKubernetesとは異なる
- API Gatewayも似た機能も持っているが、アプローチが異なる
変化点はこれだけではなく、それぞれのリリース時に周辺の依存リソースへの影響を考慮してルーティングする技術(CloudFront、Appmesh、CloudMap、Route53)と、その他リソースをバッキングサービスとして付け替えする機能、権限をロールベース・アクセス・コントロール(RBAC)とそのポリシーで制御する機能(IAM、Kubernetesのサービスアカウント)を組み合わせて全体を統制する必要がある。
そして、AWSはあくまでこれらの技術を簡単に使用できるフレームワークを提供しているだけなので、実際は利用する側の解釈と設計に委ねられる。AWSはこの問題に対するサンプル案やベストプラクティス(参考ページ:https://aws.amazon.com/jp/architecture/well-architected/?wa-lens-whitepapers.sort-by=item.additionalFields.sortDate&wa-lens-whitepapers.sort-order=desc)を提供しているが、AWSがカバーする範囲は開発フローや運用の全体像を俯瞰したものではなくAWS内部の話に限定していることに留意する必要がある。これは、AWSが情報提供している範囲外の要素も含めて全体像をイメージする必要があるということだ。
また、リリースの観点では環境変数、パラメータなどこれまで存在しない、もしくは使ってこなかった概念が出てくることに注意が必要だ。この概念の呼び方はツールや言語、環境によって異なる上に用途が複数あるのが理解を進める上で混乱を招く原因になっている。
以下に用途の例をあげる。
- 環境差分を吸収するための変数
- 任意のサービスをバッキングサービスとしてアタッチするためのパラメータ
- その両方の目的のための変数
- 環境には依存しないが汎用性をあげるためにコンフィグとして外出しされているパラメータ
- センシティブ情報(パスワードなど)
更にこれらの要素は、その扱いによって格納場所が異なる上に動的に生成される(もしくは動的に生成した方が、管理が容易になる)ものもあり、リリース時に結合されて実際の環境へ反映される。そして、上記のうち明確にコード内で定義せず、定義する場所を例示できるのはセンシティブ情報だけだが、これもまた用途・目的によって定義場所が変わる。以下に例をあげる。
| 使用する側 | 提供される機能 |
|---|---|
| Github Action | Github Secret |
| AWS Codebuild | Secrets Manager SSM ParameterStore |
| AWS CodeDeploy | SSM ParameterStore |
| AWS CloudFormation | SSM ParameterStore |
| Terraform OSS | Hashicorp Vaultなど |
| Terraform Enterprise, Terraform Cloud | ワークスペースのシークレットフラグをオンにしたパラメータ、Hashicorp Vaultなど |
| ECS | Secrets Manager SSM ParameterStore |
| EKS | KubernetesのSecret経由の任意のツール |
図1 サポートされるセンシティブデータの格納場所の例。提供される機能はあくまで例であり、本記事公開時点での情報である。
これは一例だが、これらの機能を目的別に使い分けて推奨される環境にガイドラインやベストプラクティスに従いつつ格納すべきというのが多くのドキュメントに記述されている。
それだけでなく、提供される機能は日々増えていくのも課題であり、一概にこうするのがベストであるという回答は無いかもしれない。
しかしながら、要件に応じて使用する要素についてはまとめることが可能である。サーバーレスアーキテクチャのリリース時に使われる技術の概念的ポイントだけを抜き出して以下の図にまとめてみた。
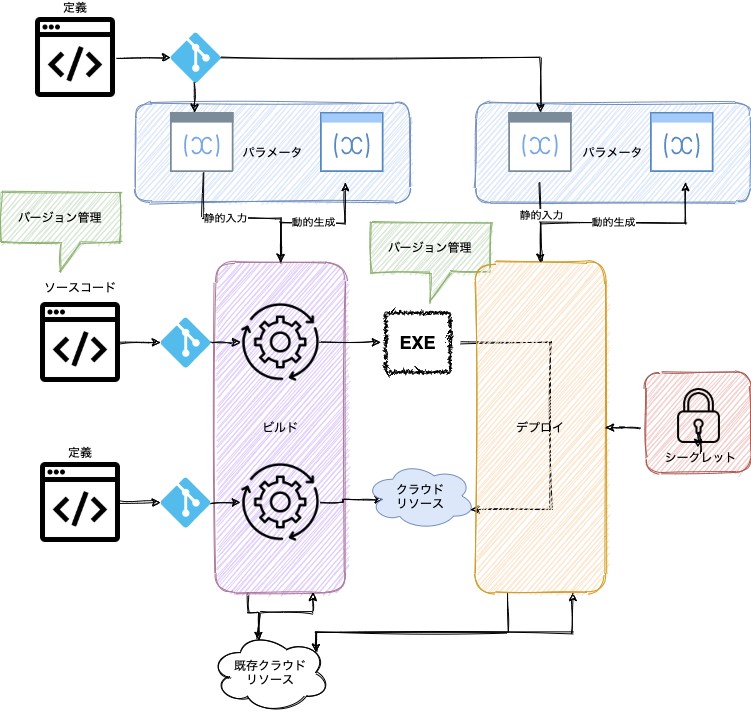
図2
図の中で示している通り、コードは大きく以下の3種類に分かれる。
- パラメータを定義もしくは生成するためのもの、及びテンプレート
- アプリケーションまたは関数、静的コンテンツのためのソースコード
- クラウドリソースを定義するためのコード
本題とは外れるが、これらを同時に管理することも使用するツール次第では出来るし、出来ない場合もある。前者はAWS CDKやPlumiがその例だ。CloudFormationは後者に該当し、Hashicorp Terraformはどちらも出来る。
CI/CDを実現した場合は、ビルドされたアプリケーションはアーティファクトと呼ばれる概念でパッケージングされ、デプロイ時にそれを利用するが、パラメータの埋め込みはビルド時・デプロイ時にそれぞれ別に定義できる。環境差分に近いものはデプロイ時に合成し、使用するリソースをバッキングサービスとして利用する。環境に依存しないものはビルド時に埋め込む。この時、同時にクラウドリソースをデプロイ時に作成もしくは更新する場合もあるし、しない場合もある。この選択はアプリケーションをリリースする対象のクラウドサービスの仕様次第である。コンテナを利用する場合は明確に分離され、ビルドする際はアプリケーション中心の視点で、デプロイする際は対象の環境を中心とした視点で分類する。Lambdaはコンテナもサポートされたため、どちらも選ぶことが出来る。また、図で示した通り実現する内容次第ではビルド時に参照する場合もあるし、デプロイ時に参照する場合もある。前者の場合は既存の環境の情報を元にパッケージングそのものを動的に定義する場合(リージョン単位でロードする機能を変えてパッケージを出力するなど)、後者はすでに解説した通り環境に合わせてパッケージの振る舞いを定義する。
最終的にリリースされるクラウドリソース(図の青地の部分)はパラメータや既存のクラウドリソースから取得した情報などを元に動的に定義されるようにするのがサーバーレスアーキテクチャではポイントとなるが、これを実現するためには「The Twelve-Factor Apps」の要件を満たさなければならないし、逆に管理上の都合から考えれば自ずと定義された形になる。
これは「鶏が先か、卵が先か」のパラドックスであり、答えはどちらでもない。あくまで「The Twelve-Factor Apps」は実現した後の結果や条件、判断基準を示しているだけであり、管理上の都合もマネージドサービスがそれに合わせた機能を持っているからそのように見えるだけでありどちらも因果関係は薄い。どちらかというと迅速なアプリケーション開発、システム開発をしようという目標とクラウドや開発技術とツールやサービスを組み合わせた結果生まれたものであり、マネージドサービスはそれに合わせて機能を追加されたと解釈したほうが無難だ。この問いは誰が何をやろうとして、その過程で副産物が生まれたかであり、副産物の方をいくら見ても解はない。「The Twelve-Factor Apps」はその目標やアプローチを理解する方が重要であり、具体的にどうやって考えるかについては「Beyond the twelve factor app」の中で解説されている。
EKS(Kubernetes)の場合は図のアプリケーションがDockerImageに相当し、クラウドリソースはKubernetesのリソースに相当する。クラウド環境においても上限は存在するが、Kubernetesの場合はそのクラスターに割り当てられたリソースによって明示的に定められているのが大きな違いだ。そして、コンテナを扱う場合はDockerImageの格納先はDockerHubやECRであり、それぞれのImageに対してタグを紐づけて管理することになるので、上図よりも視点によっては複雑になる。
2. グリーンフィールドとブラウンフィールドとサーバーレスアーキテクチャ
サーバーレスアーキテクチャの議論はクラウド導入時に言われたグリーンフィールドとブラウンフィールドの問題に近い。グリーンフィールドはソフトウェア開発の定義だが、全く新しい環境で白紙の状態から開発を行い、大きな制約や依存関係がない状態を指す。ブラウンフィールドソフトウェア開発は既存のシステムもしくはアプリケーションと共存する形で新規に開発もしくは改修を行うことを指す。グリーンフィールド・ブラウンフィールドの用語はIT業界だけの用語ではなく、様々な業界で使われている。
サーバーレスアーキテクチャ導入時においてはグリーンフィールドが強制されるのが問題である。クラウド移行時の初期は物理的な環境から、VMへの移行、クラウドのIaaS環境への切り替えはグリーンフィールド・ブラウンフィールドの選択肢があり共存も可能であった。しかしサーバーレスアーキテクチャは物理サーバーとは縁が薄く、どちらかと言うとグリーンフィールドな世界に分類される。よって、その技術を最大限に活かして導入した場合は、この概念で指摘されているデメリットがそのまま業務全体に影響してくる。
- 学習曲線が急激で、学習コストが高い
- 変化が組織に影響する
- 移行時のコストがかかる
けれども、これもまた「鶏と卵」のパラドックスであり、学習が先か後かであれば同時に、つまりやりながら覚えるものであり、変化が組織に影響するというのも組織を変化させながらやらなければ実現できない。移行時のコストはそれをどれだけ効率よくやるかという一時的な課題なので答えはブラウンフィールド開発に比べた場合、規模次第では安くなるはずだ。
つまり制約上の問題でグリーンフィールドソフトウェア開発にならざるを得ないが、スタート地点は様々でありどちらかと言うと以下の点の方が考慮すべき点である。
- どうやって学習していくか
- どこまで出来たら学習できたと判断するのか
- どうやって組織を変えていくのか
- 上記の結果から生まれたシステムへ既存のワークフローをどうやって移植するのか
どこまで出来たら学習できたと判断するのかは、決めの問題でありそこを議論しても意味はなく、また学習の材料となるものはサーバーレスアーキテクチャではないものから生まれたわけで、結果を元にいくら考察を重ねても結果には至らない。また、このパラドックスから外れるが、今のグリーンフィールドは未来のブラウンフィールドであると言う避けては通れない問題がある。
サーバーからVMへ、データセンターからクラウドへなどの流れが過去にあったが、モノシリックアプリケーションからサーバーレスアーキテクチャ・マイクロサービスの流れも同様であり、過去のグリーンフィールドが今のブラウンフィールドになっている。イメージの描き方・解釈の仕方の話になるが、実際に構築している側の目線では基盤技術に見えるものも、全体を俯瞰して見た場合はそうでは無い可能性が存在しており、事実その移り変わりが激しい。視点と主語次第で定義は変わるが、ブラウンフィールド・グリーンフィールドそれぞれに存在する課題を組織的に解決するためには、客観的な視点を培う必要があるのではないだろうか?
3. 開発フローに潜在する課題
もし議論されている手法が全て取り入れられた場合、どの様な結果になるかは「Beyond the 12 factor app」の第2章冒頭で記述されている。
(引用)クラウドネイティブアプリケーションを構築していて、コードがリポジトリにチェックインされた後、テストが自動的に実行され、リリース候補が数分以内にラボ環境で実行されているとします。世界は美しい場所であり、あなたのテスト環境は虹とユニコーンで埋め尽くされています。
実はこの文章、現実を皮肉った解説である。「虹とユニコーン」とは「あまりにも壮絶すぎて逆に畏敬の念を起こさせるような規模の大混乱に直面したときに使われる(悪い意味での)幸福感を表す皮肉」である。要約すると手段ばかりに囚われて、目的とその整理、構造の理解を怠るとこの様な状態に陥るということを指摘している。表現を変えるとリリースの方式や分類に使われる手法や手段ありきで議論を進めると、「虹とユニコーン」を存分に味わえることを示唆している。この状態はまさにグリーンフィールドが悪い意味でのブラウンフィールドになった状態とも表現できる。
この問題を回避するためには「API First」(参考記事:API-first software development for modern organizations | by Joyce Lin | Better Practices(https://medium.com/better-practices/api-first-software-development-for-modern-organizations-fdbfba9a66d3))の考え方を取り入れると良いと同書では解説している。参考記事では、欧米式のやり方を解説しているが日本に合わせて改めて本記事でまとめて見る。
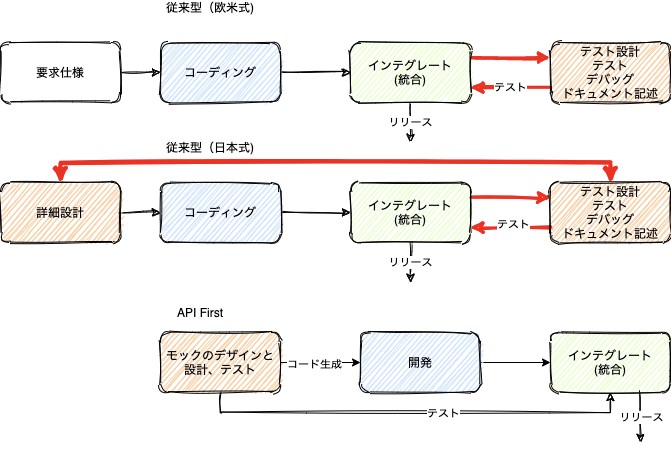
図3−1
日本で思い描かれるウォーターフォール型ソフトウェア開発プロセスは図の2番目のものである。理想は一切のミスも漏れも無く設計から開発に流れる状態を想定しているが、現実はそうでは無く、詳細設計とドキュメントの記述テストは相互に補完し合いながらコーディングとリリースを繰り返すワークフロー形態を取る。欧米式では少し簡略化されているが、どちらにしろ、いずれかの工程でミスや遅延が発生した場合は後続のワークフローにそれが影響し、依存するチームを拘束しその発生頻度に応じてループを繰り返すという問題がある。また、作成したものの評価や測定はプロセスの後半で行われるため、変更を行う場合は規模に応じて相応のコストがかかる。
対してAPI Firstではデザイン、計画、モックの開発、テストから始める。従来型と違い開発を2つのフェーズに分け、技術者と非技術者の両方のチームメンバーがプロジェクトの現状やアプリケーションにアクセスできる状態(モック)を早期に開発し、先にフィードバックを得てから後続の開発を行っても問題ないと判断した状態に遷移してから、残りの開発を行うスタイルである。
今回紹介した記事はRestfulAPI開発の場合のAPI Firstの話であるが、サーバーレスアーキテクチャ全体を見渡した場合、同様の手法が有効なワークフロー・工程が何箇所もあるのに気が付けるかどうかが課題であるが、現実世界のプロジェクトにおいてはAPI Firstの作業工程を顧客が受け入れられるか否かもボトルネックとなってくる。そして、一見銀の弾丸のように見えるこの考え方も「The Law of Leaky Abstractions – Joel on Software(漏れた抽象化の法則)」の問題が常に付いてくることを忘れてはならない。何のためにAPIを利用して何のためにAPI Firstの考え方を使い、どの様なアプローチで要求をAPI Firstで実装しリリースするのかを十分に理解して実施・維持しない場合は「虹とユニコーン」が待っている。API Firstの考え方は作業工程の無駄が省略されるだけで、認知していない他の問題も存在していた場合それが顕著に現れてくる可能性があるのだ。
またサーバーレスアーキテクチャを取り入れる以前の問題も大事だ。現在進行形で漏れた抽象化問題が発生しているからこそ「漏れた抽象化の法則」で指摘されている「いったん抽象度が定義されれば、それは具体的であると思い込んでしまい、理論が破綻してしまっている」状態になっていることに気がつく必要がある。
漏れた抽象化の問題を事前に回避し、かつすでに起きているこの問題を解決する案はいくつかある。他にも方法はあるであるだろうが以下に例をあげる。
- KJ法などを使い、抽象化された要素を分解し、再構成・再度抽象化を行うを複数回繰り返し、抽象化の漏れを減らす。メンバーの意識合わせを行う
- 変わることの少ない絶対的な尺度を用い、抽象化された概念の再整理を行う
- 0から概念を再構築する
1の手法は合意の形成、認知の共有、相互理解などのメリットがあるがメンバーが頻繁に入れ替わる際は効果が薄い。2の手法は唯物的な現実主義論だが、実際に実施しようとする場合は実行する側も説明を受ける側もそれ相応の前提知識が必要となり、実現性は薄い。3の方法は効果的だが現実世界では投資対効果が低い。しかも、IT技術ではなく領域としては認知科学の世界になってしまう。認知科学の専門家でも実現の難易度は高いであろう。実現が可能不可能であれば可能であろう。この話は認知の問題から来ているとも言えるからだ。どのような手法を採用するにしても時間・メンバー・コスト効果の問題が常に付随してくる。しかし、以下の問題を解決しなければ常に同じ結果が待っている。
- 抽象化によって作業時間は短縮される、学ぶ時間は短縮されない
- 抽象化された環境での問題解決は、されていない環境に比べて莫大な時間を要する
様々な設計プロセスの研究を行なっているデイビッド・C・ウィン博士はその論文(参考記事:https://www.researchgate.net/publication/299634192_Perspectives_on_iteration_in_design_and_development)の中で「プロセス改善を達成するための銀の弾丸のようなアプローチはまだ存在しない」と述べている。この問題の解決のアプローチについては様々な手法が考案され、博士の論文の中でもそれぞれについて調査がされているが、解は出ていない。
前置きが長くなったが問題を整理してみよう。開発工程と呼ばれるものは、図3−2で示す工程を体系的にまとめたものである。これに人(のアサイン)の要素と時間の要素、現代の技術を加えて要素を並び替えて効率的に進めようという考え方がAPI Firstと解釈できる。
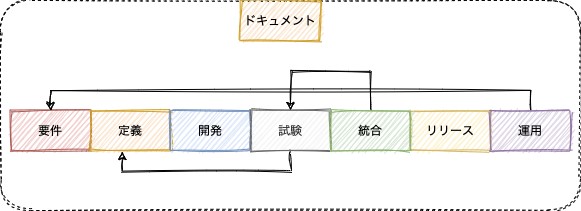
図3−2
しかし、実際の要件は本来プロジェクトオーナーもしくは顧客が欲しかったものを細分化したものであり、図3−3で示す構造の右側の最適化が進めば進むほど、本来の要求との関連付けと管理が難しくなっていく。
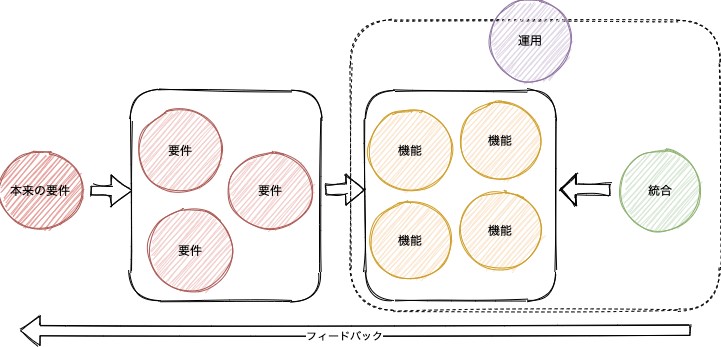
図3−3
この構造の潜在的な問題点としては以下の通りだ。
- 1.ビジネス的な外的要因で本来の要件は動的に変わる
- 2.開発したシステムからのフィードバックで新しいアイデア、もっと良いやり方が見つかり要件が変わる
- 3.技術要素とそれを持つ人的リソースの効率的なアサインの問題
- 4.時間の問題
- 5.システム自体から発生するコストの問題
CI/CDやマイクロサービスといった考え方・手法はこれらの問題のうち一部を効率的に解決する手法であって全体を俯瞰したものではない。特定の領域の課題・問題を以下の判断基準を元に効率的にやるための手法であって、必ずやらなければならないことに関しては変わっていない。
- 1.コスト
- 2.時間
- 3.人のリソース
今回の記事の場合はサーバーレスアーキテクチャになるが、選択した技術や機能の組み合わせにより効果的に統合する手法や結果はケースバイケースになる。そしてアジャイル開発などの理論でも指摘されているがステークホルダも実際にこれらを実現する技術者もこれらのプロセスを通過・試行錯誤する過程や結果で成長し、考えや意見が変わるのだ。同時に利用する技術やツール、マネージドサービスも流動的に変化するため、万能薬的なものは存在しない。
コストや実際に目の前にいるメンバーのスキルを元に、本来の目的に対してどのような手法を一時的に使って解決を図り、その結果と過程を元に成長したメンバーと共に次はどのような手法を一時的に採用して、変化した本来の目的をその時その場で実現するかが命題で、手法や解釈の方に比重を置いては「虹とユニコーン」からは逃れられない。













